Frameworks Against Ignoring Future AI Risks
More productive ways to model, engage with, and form strategy around future AI risks.

Introduction
The following will be mostly meta commentary. It will mostly discuss social dynamics, decision making, and principles that cultivate the circumstances that allow us to reach a more whole truth and prudent allocation of resources. I will be doing a lot of intuition pumping here with many example scenarios to try to paint a clearer picture.
Ultimately, this is more of a journey through how minds can better approach the truth and make strategic decisions with all the barriers, biases, and tradeoffs that usually block us. It is less of a technical argument about the nature of intelligence or anything else. In fact, I’ll discuss why I think that starting place is less productive.
To begin, I’ll talk about the highly consequential thresholds of AI capability that I think matter most with respect to future AI risks. Given this more productive framing, the question will arise of how we should navigate this uncertainty.
How can we estimate when these thresholds will be crossed? How should we think about acting against these risks today?
I will argue that there are more balanced, principled approaches to shared truth seeking and resource allocation that we can and ought to take.
Outline
Here is an outline of what you will see in this blogpost.
Consequential Capability Thresholds: Outlines specific AI capability thresholds that could pose large scale risks, regardless of the exact nature or architecture of AI systems.
How We Got Here: Examines how different subgroups in the AI sphere formed their beliefs through processes of cause and effect.
How We Usually Find The Truth: Discusses the challenges of trusting experts and institutions in a world flooded with contradicting information and skepticism.
Sowing the Right Seeds for Truth-Seeking: Proposes a series of principles designed to cultivate individual attitudes and shared environments that promote the quality of healthy dialogue that allows all to approach the truth in mutual good faith.
Resource Allocation amidst Uncertainty: Argues for a nuanced approach to resource allocation that considers multiple possible outcomes rather than focusing solely on the most likely scenario.
Conclusion: Summarizes key points about considering future AI risks, improving epistemics, and balancing resource allocation across different AI-related priorities.
Sign Off: Reflection on the evolution of these debates.
Consequential Capability Thresholds
Since it’s already fairly obvious that we should be concerned with present harms, I won’t take time to justify them. Systemic consequences and harms matter. Lives are hurt when with intervention they could possibly not be. They do have to be balanced out with the benefits of innovation, but they clearly matter. It’s obvious. Everyone should believe this. The only few who don’t are (1) a small subset of very radicalized people with respect to existential risk and (2) some people with political agendas or financial incentives that lead to stances that are pro free market and/or contra confronting systemic issues.
The bigger barrier to break through from my vantage point is justifying that future risks matter. It seems to me that a pretty sizable portion of the AI field has this perspective – that they are science fiction, nonsense, and shouldn’t be on anyone’s minds.
This makes me sad. I don’t want to be sad.
So, let’s contextualize why it is so controversial.
Oftentimes, a massive crux on the question of whether future AI risks are real or not is dependent on how you define/what you generally think about AGI:
Are today’s LLMs already early AGI as many of the frontier labs believe? Can we just scale training compute and improve LM Agent scaffolding to reach AGI? Will scaling inference compute like OpenAI’s new o1 model does make this even more easy?
Do we need a more brain-like architecture to reach AGI as Yann LeCun believes? Do we need modular components that each serve a purpose like world modeling, executive decision making, memory, and so on? Do we need System I and System II like structures?
What does it mean to be human-level? What even is human intelligence in the first place? Do humans really reason from first principles at every step of the way or do we mostly reference strong associations we’ve already built up?
Is the singularity possible? Can something exponentially grow in intelligence so fast that it is impossible to predict or control? What physical constraints are there here like a limitation on how fast parts can be manufactured or how much energy we can produce nationally?
What will a superintelligent AI look like? What will it be capable of? Will it be able to create diamond nanobots that infect our bloodstream and can kill us on a moment’s notice without us being aware at all?
I want to encourage you to throw this framing away. We don’t really need it in order to think about these problems. Leave it out of mind. Gone.
People tend to have wildly different intuitions about the nature of intelligence and consciousness that are nearly impossible to bridge over.
While interesting, it seems that engaging conversation within this framework leads to very unproductive dialogues that hyperfixate on the fundamental nature of intelligence itself.
Instead, let’s look at things through the lens of capability thresholds.
Here, it doesn’t matter whether it’s a highly performant LLM, a brain-like architecture, a highly specialized model, or anything else. Only the thresholds of capability that have been crossed vs. haven’t been crossed matter.
If we reach these thresholds, then certain societal scale risks necessarily must arise.
If we don’t reach these thresholds, then certain societal scale risks necessarily will not yet have arisen.
It is clear cut. It is undebatable. It doesn’t require any philosophy on the nature of intelligence. It doesn’t require hand wavy predictions on what an AI will look like in 100 years. It doesn’t require exploration of fundamental constraints of physics. It is easy and straightforward.
Here are the thresholds of capability that I want you to worry about:
Mass Social Engineering: AI systems crafting hyper-targeted misinformation campaigns at scale. Could manipulate public opinion, sway elections, create sleeper agents, or incite social unrest by exploiting reasoning biases across entire populations.
Mass Surveillance: AI-powered systems enabling pervasive monitoring and analysis of individuals' activities, communications, and data. Risks include erosion of privacy, potential for abuse by authoritarian regimes, chilling effects on free speech and association, and creation of detailed psychological profiles for manipulation or control.
Autonomous Weapons: AI-powered weapons making kill decisions without human input. Risks include lack of human judgment in complex scenarios, potential for unintended casualties, and rapid escalation of conflicts.
CBRN Weapons: AI enhancing development and deployment of Chemical, Biological, Radiological, or Nuclear weapons. May optimize designs, improve delivery, or assist in attack planning, dramatically increasing destructive potential.
Autonomous Agents: Advanced AI acting autonomously to achieve complex goals in real or digital worlds without human supervision. From personal assistants to systems managing critical infrastructure to metaconglomerate CEOs, risks stem from far-reaching decisions made without full oversight or understanding, incentives for power seeking/outcompeting humans, and irreversible entanglement with our world infrastructure and economy.
AI R&D Feedback Loop: AI systems engaging in AI research, which improves future AI versions, which allows them to engage in higher quality research, and so on. Risks stem from this feedback loop being executed without sufficient oversight, outpacing human checks and managements, resulting in unpredictable and difficult to control outcomes.
For each of the above, there is the risk of both (1) the concentration of power in a government or corporations’ use of these capabilities and (2) the democratization of power to a significantly larger count of individual bad actors than currently have these capabilities.
How we will maintain healthy and balanced equilibriums here remains a massive open uncertainty. The systems of law, policing, national security, geopolitical diplomacy, etc. that keep us safe today may have a challenging path if they hope to generalize to tomorrow.
Returning to the point: The above risks necessarily follow from a certain capability threshold of AI models coming into being. They do not require “AGI”. It might not even be a multimodal foundation model that accomplishes them. It could just be a small specialized model for all we know.
Regardless, they are scary. We should not bury our heads in the sand and ignore them.
How confidently can you say that within 10 years we won’t have any of these capability thresholds reached? What about 15 years? What about 20? What about 25?
I don’t think anyone can look at this given how fast recent AI developments have been and confidently say a probability that is exceptionally small such that we should disregard it.
Think seriously about this. It matters.
You don’t have to think that AI is going to end the world and think to yourself “Gosh, in light of that, what is even the point of eating breakfast today.”
All you have to do is step back and say, “Wow, these capabilities seem plausible in the not too distant future and…that matters.”
You don’t have to think that it will end the world.
You do have to take a step back and consider whether at a minimum, these should land in a category national security concerns of a similar level to: Energy Security, Climate Change, Supply Chain Vulnerabilities, Great Power Competition, Pandemic Preparedness, Cybersecurity, Terrorism, Weapons of Mass Destruction, and so on.
If you think there is a reasonable chance we see these capabilities on a not extensive timeline, then AI becomes a national security concern.
If AI is a national security concern, well, then we should probably allocate some resources towards it.
This is really not a radical step or leap here.
I encourage you to consider it.
How We Got Here
The following will assume that you don’t think that future AI risks are completely implausible and that you don’t think that they are entirely guaranteed. In other words, it assumes you are reasonable.
[sorry for the lack of sugar coating here, but I do want to try to cut through some noise.]
There are many different beliefs in different subpopulations of the AI sphere. To totally unfairly oversimplify:
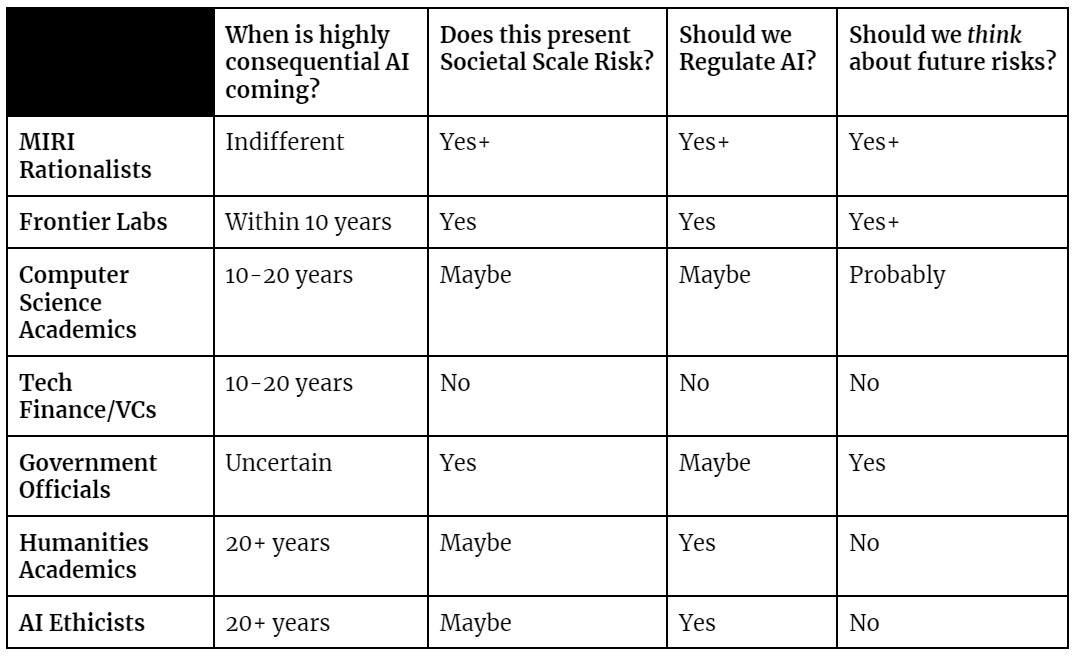
Let’s look at these beliefs as what they are: a product of a chain of cause and effect. The networks of people they talk to, the media stories they see online, and the broader political worldview they have all are a part of this chain.
For example, say we have an academic in Computer Science who:
Has been working on the enduring technical challenges of improving AI for decades.
Is compute constrained and has their research really benefit from the open sourcing of large scale models.
Politically leans left but very moderately.
Gets their news from ABC, the Washington Post, and sometimes Twitter.
Has a social network that consists of their family, some similar STEM-ie friends, other computer science academics, and some humanities oriented administrators that they talk to every so often but not in too much depth.
What do you think is most likely that this person will believe? They probably will believe that:
We are pretty far from highly consequential AI.
The harms of bias, fairness, and robustness are real.
We should maybe regulate AI to make sure it doesn’t harm people? But, certainly not in a way that stifles open innovation and research.
We should continue open source AI to promote research and science.
The long term risks maybe make sense but it isn’t happening any time soon so why freak out now.
The AI panic is by people who don’t really know what’s going on in AI.
We should not pause AI development any time soon.
Now, what is the probability of them believing otherwise given their experiences? Not very high.
They only would believe otherwise on the small probability that perhaps they read a longer book that convinced them, or they attended a conference workshop which convinced them, or they have a friend who frequently argues for it, or some other low probability event.
None of the parts of the chain of cause and effect mean that anyone is wrong, necessarily.
However, they are a more accurate lens to look through to see how we came to this landscape of beliefs: Through a fundamentally imperfect reasoning process informed by offhand experiences that cumulatively equilibrate out across an individual’s life.
The only way this would NOT be the case is if someone sat down at a desk, did an extensive review of all of the sources of evidence, wrote a very long argument evaluating all sides, and came to a carefully reasoned conclusion over the course of several months. Who the hell has time for this?
[some people: AI Snake Oil]
How We Usually Find The Truth
Commonly in society, when average people don’t know what’s going on at all and only the experts have taken the time to really dig in, what we do is trust those experts. For example, during global pandemics, we generally are supposed to trust the epidemiological experts and the cumulative decisions that their institutions come to on the basis of extensive research, right?
Clearly this is no longer the structured and controlled way that our world works. The world we live in today is too full of flooding and contradicting information. People with large platforms are skeptical, as is their right, and share this skepticism to their massive audiences online. People in their audiences eat it up, people not in their audiences fight back only giving it more attention, And so on the cycle goes.
Institutions can and ought to do their best to combat this and rebuild trust in them. However, this is a serious challenge. And, particularly for AI, there aren’t any well established governmental institutions yet.
The problem here is that it’s hard to tell what is the truth and what isn’t. Once you define something as misinformation, you better be very certain that it is. Otherwise if it later comes out that it isn’t, people will lash out at you in a big way.
Let’s be realistic, these dynamics are nearly irreversibly a part of our world. There’s no going back to the 1970s status quo of one general mainstream media truth that all believe in. And, to be honest, it’s not clear whether going back would be better in the first place.
Yes, today is incredibly messy. But, more information is generally good and gives us more opportunity to derive the truth. The only downside is that it also gives us more opportunity to be wildly confused and/or intentionally misled.
However, with the right systems in place, this can almost certainly become more truthful at the end of the day than whatever we previously had. Even with more noise than ever, we also now have more access than ever to the ground truth, if only we can sift and winnow to it.
As my very own University of Wisconsin-Madison puts it:
“UW–Madison’s mission is, in part, to generate and share knowledge through a broad array of scholarly, research and creative endeavors, and to strengthen cultural understanding by providing opportunities for people to study the implications of social, political, economic, and technological change.
Inherent in this mission is the need for the free exchange of ideas through open dialogue, free inquiry, and healthy and robust debate. This is a longstanding priority of our campus, captured by our now-famous language about the importance of “that fearless sifting and winnowing by which alone truth can be found.”
Sowing Seeds to Approach the Truth
Let’s return to thinking about the AI risks. The beliefs of several subpopulations here contradict in certain regards. This is obvious in looking at the above table. Everyone can’t all be right at once. So, what is what?
We don’t know. All that we know is that the only way to further uncover the truth is to have conversations. We need to promote venues for the healthy, respectful sparring and equilibration of the best ideas, as my university so eloquently states.
But, this is very challenging. We never, ever are dispassionate agents of debate who talk back and forth, riling out the facts and sorting out the truth in a robotic way. We are emotional beings with egos, attachments, traumas, life goals, and so on that make us invested in “our side.”
Imagine being someone who had an ectopic pregnancy, could not abort the baby due to the overturning of Roe v. Wade, and ended up losing their fertility/ability to have a future child. Are you going to be dispassionate in debate around abortion rights even when it's not going in your favor? Probably not.
Imagine being an academic whose professionalism and reputation is what grants them access to collaborators, grants, awards, and high leverage career positions. Are you going to attempt to discuss your opinions about controversial subjects in a nuanced way, even if that might sour your reputation in the eyes of a subset of your colleagues who end disagreeing? Especially in academia where you are held to a higher standard of moral righteousness? Probably not.
Imagine being anonymous on Twitter where there are no consequences on your life and in 160 characters you have to posture as much as you can to create the best tweet that will get you views, likes, and followers so that your influence can grow and you can “use it for good.” Are you going to be good faith and charitable towards the person you are replying to when it's not going in your favor? Probably not.
However, we ultimately do have the agency to change this:
We can cultivate environments where it is okay to be wrong. We can create environments explicitly designed and framed to give grace to speakers to allow them to say what their honest, humble opinions are (so long as they don’t have an aptitude that makes them tend to take up all the air on stage, quiet everyone else out, rain moral outrage upon someone, etc. outside of a reasonable margin – in some extreme cases obviously it may be justified). We can build a culture where even if two people mutually disagree, they allow each other to calmly speak their piece and they accept each other.
We can lower the stakes of conversations and accept the fact that in order to sift and winnow to the truth, somebody necessarily has to be wrong. This is not something to be frustrated over. It is a necessary state of the world to see with eyes open and drop any silly expectation otherwise. Could there be a world where no one is wrong ever, given the pathway our history has taken thus far? If not, then why get angry about it?
We can be compassionate to those who have suffered personally or know others who have suffered as a result of the topic being discussed and be soft with them. We can decide to not push hard on this subject while in their presence – unless they think that they are able to more softly discuss the subject. We can be patient and wait for a less loaded opportunity to have these discussions.
We can promote Scout Mindsets where every individual is encouraged to go out and seek the truth on their own, including referencing well-respected institutional perspectives, rather than agree with what the people around them are saying.
We can make a core goal to come to more accurate shared descriptions of reality before we go further and make our value loaded normative judgements.
We can have genuine and principled care in the means of giving everyone a fair chance to speak and be heard, even if you ultimately disagree with them.
Only this quality of commitment to principles will allow us to move towards the truth even when it isn’t convenient for us. In the words of John Adams who in 1770 famously took the controversial position of lawyer for the British Soldiers who committed the Boston Massacre because he knew it was their fundamental right to have representation:
I had no hesitation in answering that Council ought to be the very last thing that an accused Person should want in a free Country … And that Persons whose Lives were at Stake ought to have the Council they preferred … and that every Lawyer must hold himself responsible not only to his Country, but to the highest and most infallible of all Trybunals for the Part he should Act.
Resource Allocation amidst Uncertainty
Even with a gradual approach towards better perspectives, there still will remain uncertainty.
However, even when there are different pathways that we are uncertain of, I want to argue that the best decision is not to just believe in and select what you find to be most likely.
This is binary thinking – black and white.
Say that A, B, C are a partition of a probability space, where the probability of A is 0.1, B is 0.35, and C is 0.55. Say that A has the highest reward, and B and C have equal medium rewards.
[no, the following is not about p(doom), please don’t pattern match that here.]
This does not necessarily mean that it is only worthwhile to invest in C. It also does not necessarily mean that it is only worthwhile to invest in A and C.
If you had the constraint of only needing to pick one or two, this would be true. However, there are many circumstances when this is not the case at all. Cases where you or your organization straightforwardly has enough bandwidth to be working on all three. The problem is that even in these cases, we sometimes suboptimally decide to only select one.
Instead, if you are an organization with sufficient capacity, then realistically you should be working on all three outcomes: A, B, and C. The reason simply is that if any one individual outcome works out, then you are net rewarded. Therefore, as long as investing in all 3 is within your ability, there is no reason not to.
1) If there are aspects of your organization with more surplus where you can delegate work away from them without affecting the outcomes, do so.
Say you have workers for A that are bottlenecked by certain factors, leaving them with an extra 3 unfilled hours in their work day. Have them work on B or C.
2) If there are factors making the work between A, B, or C overlap so that doing one promotes the other, do so.
Say you are a university with thousands of college students. Say that promoting both B and C together garners student attention and motivates them to get involved with organizations, research, and perhaps ultimately careers in the overlapping space of B and C. Promote B and C together to students.
3) If there are political factors between A, B, and C such that abandoning or taking power away from one hurts the others, which will likely always be the case, do not do so.
Say you know that if you totally abandon or take power from A, they will become very upset and vocal about it. Say that this flak would ultimately end up hurting the bandwidth of B and C because they now have to deal with these upset people and have individuals slinging mud at them, lowering their overall reputation, perhaps funding, etc.
[realistically, most scenarios involving a prioritization/delegation between people will fall into this category if those who end up losing the most have the means to fight back.]
4) Now, if there are factors like a limited financial budget or limited personnel, then you might have to make tough decisions.
Say you only have X amount of work hours that you can delegate between developing the agendas for A, B, or C, and you really have to pick between them in a zero sum way. In this case, a holistic evaluation is required that takes into account the second and third order effects of the decision including the political factors at play.
This is genuinely fair. But, be careful. It seems to me that oftentimes shortcuts are made and people act like there is a zero sum scenario at play when it is not the case.
Again, it may be the case. But, be careful. There probably are at a minimum a couple of ways that you can dip your hands in both baskets.
Conclusion
If you are reasonable, in other words don’t think that future AI risks are completely implausible and don’t think that they are entirely guaranteed, then the best actions for you to take are pretty clear:
1) Realize that you should think about future AI risks not in the framing of some wacky, hard to pin down definition of “AGI” but instead in the clear-cut framing of capability thresholds.
It doesn’t matter whether it is a highly performant LLM, a brain-like architecture, a highly specialized model, or anything else. Only the capability thresholds matter.
If we reach these, then certain societal scale risks necessarily must arise.
If we don’t reach these, then certain societal scale risks necessarily will not yet have arisen.
Again, these risks are:
Mass Social Engineering
Mass Surveillance
Autonomous Weapons
CBRN Weapons
Autonomous Agents
AI R&D Feedback Loop
2) Cultivate the circumstances where you can have the best epistemics to understand the nature of AI and the cost benefit analysis of confronting these problems.
Let’s be realistic. Your beliefs are a product of a chain of cause and effect and there are many links in that chain which if they were different, as a product of chance, you would have a different belief.
Individually, do your best to challenge yourself with different opinions and reinforce your beliefs as an individual.
Organizationally, do your best to create circumstances where healthy and mutually respectful dialogue can occur, even around challenging subjects.
Create systems that increase the probability that your future chain links will point you in the correct direction.
3) In any decision where you can invest without tradeoff in advancing AI, acting on the ethical consequences of AI, and mitigating large scale risks of AI, do all three.
Let’s be realistic. Sometimes there are zero sum situations where you have to invest in one at the cost of the rest. However, I’d posit that much more often than you think, you aren’t truly constrained in this way. You still can and ought to invest in several lanes.
Individually and Organizationally, take some time to question how much you really only need to only prioritize the thing you most believe in or agree with at the cost of all of the rest.
Sign Off
I hope that all of the above landed with you.
It has been really interesting to see the politics of this space evolve over time.
May this be an equilibrating force that helps clear up some muddied waters.